

Deze blog is tot stand gekomen in samenwerking met Fan Bu, Jason Mackay, Borya Sobolev, Dev Khanolkar, Ali Dabir, Puneet Kamal, Li Zhang en Lei Jin.
“Alles is een bestand”; sommige zijn databases
Invoering
Machinegegevens vormen de basis van waarneembaarheid en diagnose in moderne computersystemen, inclusief logboeken, statistieken, telemetrietraceringen, configuratiesnapshots en API-responspayloads. In de praktijk worden deze gegevens ingebed in prompts om een doorschoten compositie te vormen van instructies in natuurlijke taal en grote, door de machine gegenereerde payloads, doorgaans weergegeven als JSON-blobs of Python/AST-letterlijke waarden. Hoewel grote taalmodellen uitblinken in het redeneren op basis van tekst en code, worstelen ze vaak met door machines gegenereerde reeksen, vooral als ze lang en diep genest zijn en worden gedomineerd door repetitieve structuren.
We observeren herhaaldelijk drie faalmodi:
- Tokenexplosie van woordenstroom: Geneste sleutels en zich herhalende patronen domineren het contextvenster en fragmenteren de gegevens.
- Contextrot: Het model mist de ‘naald’ die verborgen zit in grote ladingen en wijkt af van de instructies.
- Zwakte in het redeneren van numerieke/categorische reeksen: Lange reeksen verbergen patronen zoals afwijkingen, trends en relaties tussen entiteiten. Het knelpunt gaat niet alleen over de lengte van de inputs. Machinegegevens vereisen in plaats daarvan structurele transformatie EN signaalverbetering zodat dezelfde informatie wordt gepresenteerd in representaties die zijn afgestemd op de sterke punten van een model.
“Alles is een bestand”; sommige zijn databases
Anthropic heeft met succes het concept gepopulariseerd dat “bash alles is wat je nodig hebt” voor agentische workflows, met name vibe-codering, door volledig te profiteren van het samenstelbare bash-bestandssysteem en de tooling. In context-engineering-omgevingen met veel machinegegevens stellen we dat databasebeheerprincipes van toepassing zijn: in plaats van het model te dwingen om onbewerkte blobs rechtstreeks te verwerken, kunnen high-fidelity payloads worden opgeslagen in een gegevensarchief, waardoor de agent deze kan bevragen en geoptimaliseerde hybride gegevensweergaven kan genereren die aansluiten bij de redeneersterkten van LLM met behulp van een subset van eenvoudige SQL-instructies.
Hybride dataweergaven voor machinedata: “Eenvoudige SQL is wat je nodig hebt”
Deze hybride weergaven zijn geïnspireerd op het databaseconcept van hybride transactionele/analytische verwerking (HTAP), waarbij verschillende gegevensindelingen verschillende werklasten bedienen. Op dezelfde manier onderhouden we hybride representaties van dezelfde payload, zodat verschillende delen van de gegevens effectiever kunnen worden begrepen door LLM.
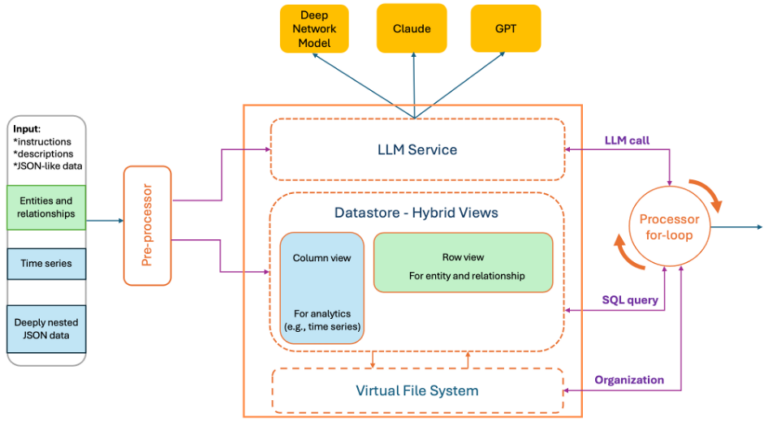
Daartoe introduceren wij ACE (Analytische Context Engineering) voor machinedata: een raamwerk voor het bouwen en beheren van analytische context voor LLM. ACE combineert een virtueel bestandssysteem (toewijzing van waarneembaarheids-API’s aan bestanden en transparante onderschepping van Bash-tools om niet-schaalbare MCP-oproepen te vermijden) met de eenvoud van Bash voor intuïtieve organisatie op hoog niveau, terwijl managementtechnieken in databasestijl zijn geïntegreerd om nauwkeurige, gedetailleerde controle over gegevensinvoer op laag niveau mogelijk te maken.
Diep netwerkmodel – ACE
ACE wordt gebruikt bij de redenering van het Cisco AI Canvas-runbook. Het converteert onbewerkte aanwijzingen en machinepayloads naar hybride weergaven in contexten met verklaringen die LLM’s betrouwbaar kunnen gebruiken. ACE is oorspronkelijk ontworpen om het Deep Network Model (DNM) te verbeteren, een LLM die specifiek door Cisco is gemaakt voor netwerkdomeinen. Om een breder scala aan LLM-modellen te ondersteunen, werd ACE later geïmplementeerd als een zelfstandige service.
Op hoog niveau:
- Een preprocessor parseert de gebruikersprompt, die natuurlijke taal en ingebedde JSON/AST-blobs als een enkele string bevat, en produceert hybride datavisualisaties samen met optionele taalkundige samenvattingen (bijvoorbeeld statistieken of afwijkende sporen), allemaal binnen een gespecificeerd tokenbudget.
- Een data-archief bewaart een getrouwe kopie van de originele machinegegevens. Hierdoor kan de LLM-context klein blijven en toch volledige antwoorden mogelijk zijn.
- Een for-loop-processor inspecteert de LLM-uitvoer en ondervraagt voorwaardelijk de gegevensopslag om de respons te verrijken, waardoor een compleet en gestructureerd eindantwoord ontstaat.
Rij + Kolom georiënteerdar-weergaven
We genereren complementaire representaties van dezelfde payload:
- Kolomvormige weergave (veldgericht). Voor analysetaken (bijvoorbeeld lijn-/staafdiagrammen, trends, patronen, detectie van afwijkingen) transformeren we geneste JSON in afgeplatte gestippelde paden en reeksen per veld. Dit elimineert herhaalde voorvoegsels, maakt gerelateerde gegevens aaneengesloten en vergemakkelijkt berekeningen per veld.
- Lijngeoriënteerde weergave (ingang gericht). Ter ondersteuning van relationeel redeneren bijvoorbeeld ha-een EN is-een relaties, inclusief lidmaatschap van entiteiten en associatiemining: we bieden een rij-georiënteerde representatie die recordgrenzen en lokale context tussen velden behoudt. Omdat deze visie geen intrinsieke ordening tussen rijen oplegt, maakt het uiteraard de toepassing van statistische methoden mogelijk om inzendingen te rangschikken op basis van relevantie. Concreet ontwerpen we een aangepast TF-IDF-algoritme, gebaseerd op de relevantie van de zoekopdracht, woordpopulariteit en diversiteit, om rijen te classificeren.
Weergaveformaat: We bieden meerdere formaten voor het weergeven van inhoud. Het standaardformaat blijft JSON; Hoewel dit niet altijd de meest token-efficiënte weergave is, leert onze ervaring dat dit meestal het beste werkt met de meeste bestaande LLM’s. Daarnaast bieden we een aangepast weergaveformaat, geïnspireerd op het open source TOON-project en Markdown, met een aantal belangrijke verschillen. Afhankelijk van de neststructuur van het schema worden de gegevens weergegeven als compacte platte lijsten met gestippelde sleutelpaden of met behulp van een ingesprongen weergave. Beide benaderingen helpen het model structurele relaties effectiever af te leiden.
Het concept van een hybride visie is goed ingeburgerd in databasesystemen, vooral wat betreft het onderscheid tussen rij-georiënteerde en kolom-georiënteerde opslag, waar verschillende data-indelingen zijn geoptimaliseerd voor verschillende werklasten. Algoritmisch bouwen we een ontleedboom voor elke letterlijke JSON/AST-blob en doorkruisen we de boom om selectief knooppunten te transformeren met behulp van een eigenzinnig algoritme dat bepaalt of elke component het beste wordt weergegeven in een rij- of kolomgeoriënteerde weergave, terwijl de instructiegetrouwheid onder strikte tokenbeperkingen behouden blijft.
Ontwerpprincipe
- ACE volgt een principe van eenvoud en geeft de voorkeur aan een klein aantal generieke tools. Het integreert analyses rechtstreeks in de iteratieve redeneer- en uitvoeringslus van LLM, waarbij een beperkte subset van SQL samen met Bash-tools op een virtueel bestandssysteem wordt gebruikt als native mechanismen voor gegevensbeheer en -analyse.
- ACE geeft prioriteit aan optimalisatie van contextvensters, waardoor het redeneervermogen van LLM binnen begrensde aanwijzingen wordt gemaximaliseerd, terwijl een volledige kopie van de gegevens in een externe gegevensopslag wordt bewaard voor op zoekopdrachten gebaseerde toegang. Zorgvuldig ontworpen operatoren worden toegepast op kolomvormige weergaven, terwijl classificatiemethoden worden toegepast op rijgerichte weergaven.
In de productie zorgt deze aanpak voor een dramatische vermindering van de promptomvang, de kosten en de latentie van gevolgtrekkingen, terwijwijl de kwaliteit van de reacties wordt verbeterd.
Illustratieve voorbeelden
We evalueren het tokengebruik en de responskwaliteit (gemeten door een LLM-redeneerscore als rechter) voor representatieve werkbelastingen in de echte wereld. Elke werklast omvat onafhankelijke taken die overeenkomen met individuele stappen in een workflow voor probleemoplossing. Omdat onze evaluatie zich richt op prestaties in één stap, nemen we geen volledige agentdiagnosetrajecten met tooloproepen op. Naast het aanzienlijk verminderen van het tokengebruik, bereikt ACE ook een hogere responsnauwkeurigheid.
1. De scheur opvullen:
Netwerkrunbookprompts combineren instructies met JSON-gecodeerde tabblad- en chatstatus, eerdere variabelen, hulpprogrammaschema’s en gebruikersintentie. De taak is om een handvol velden boven te halen die begraven liggen onder ladingen van dichte, repetitieve machines.

Onze aanpak reduceert het gemiddelde tokenaantal van 5.025 naar 2.350 en repareert 42 fouten (van de 500 tests) vergeleken met het rechtstreeks aanroepen van GPT-4.1.
2. Abnormaal gedrag:
De taak is het beheren van een breed spectrum aan machinegegevensanalysetaken in observatieworkflows.

Door operatoren voor anomaliedetectie toe te passen op kolomweergaven om aanvullende contextuele informatie te bieden, verhoogt onze aanpak de gemiddelde responskwaliteitsscore van 3,22 naar 4,03 (van de 5,00), een toename van 25% in nauwkeurigheid, terwijl een vermindering van 44% in het tokengebruik over 797 steekproeven wordt bereikt.
3. Lijndiagram:
De invoer bestaat doorgaans uit metrische gegevens uit tijdreeksen, die bestaan uit reeksen meetrecords die met regelmatige tussenpozen worden verzameld. De taak is om deze gegevens weer te geven met behulp van frontend-diagrambibliotheken.

Het rechtstreeks aanroepen van LLM resulteert vaak in onvolledige gegevensweergave vanwege lange uitvoerreeksen, zelfs als de invoer binnen het contextvenster past. In de afbeelding hierboven produceert LLM een lijngrafiek met slechts 40-120 punten per reeks in plaats van de verwachte 778, wat leidt tot ontbrekende gegevenspunten. Op 100 testvoorbeelden, zoals weergegeven in de volgende twee figuren, bereikt onze aanpak tokenbesparingen van ongeveer 87%, reduceert de gemiddelde end-to-end latentie van 47,8 s naar 8,9 s en verbetert de responskwaliteitsscore (similarity_overall) van 0,410 naar 0,786 (van 1,00).
 BRON
BRON
Paul Arends
“Ik ben Paul Arends, afgestudeerd in Bedrijfskunde aan de Universidad Complutense en met een master in Personeelsmanagement en Organisatieontwikkeling aan ESIC. Ik ben geïnteresseerd in netwerken en social media en richt mijn professionele ontwikkeling op talentmanagement en organisatieverandering.”
 Paul Arends
Paul Arends- Cisco
- februari 4, 2026
- 1 views
Functies en toepassingsgebieden van AI-beveiliging in organisaties
Wanneer uw CISO tijdens de volgende bestuursvergadering spreekt over ‘AI-beveiliging’, waar heeft hij het dan precies over? Gaat het over het beschermen van uw AI-systemen tegen aanvallen? Gebruikt hij AI…

- Paul Arends
- Cisco
- februari 4, 2026
- 2 views
Handleiding ontwikkelaars Cisco Live EMEA 2026: AI, automatisering en Meraki
Kom ons bezoeken op Cisco Live EMEA 2026 9-13 februari 2026 Cisco Live EMEA 2026 belooft een van de belangrijkste evenementen te worden die nog steeds gericht zijn op ontwikkelaars…




