

Deze blog is geschreven in samenwerking met Yuqing Gao, Jian Tan, Fan Bu, Ali Dabir, Hamid Amini, Doosan Jung, Yury Sokolov, Lei Jin en Derek Engi.
LLM’s klinken misschien erg overtuigend, maar bij netwerkoperaties is goed kijken niet voldoende.
Netwerkactiviteiten worden gedomineerd door gestructureerde telemetrie, lange configuratiestatussen, grootschalige tijdreeksen en onderzoeken die apparaten, sites en domeinen omvatten. De praktische beperking is niet of een AI-model een netwerkvraag op zichzelf kan beantwoorden. De vraag is of het AI-systeem kan redeneren op basis van echte operationele gegevens, de netwerk- en bedrijfscontext kan begrijpen, details kan behouden die de uitkomsten veranderen, en betrouwbaar kan blijven bij multi-shift-interacties, inclusief probleemoplossing.
Dit stelt duidelijke eisen aan technische en zakelijke besluitvormers: als je wilt dat AI netwerkoperaties ondersteunt, moet het ontworpen zijn om netwerkgegevens en netwerkworkflows te gebruiken, en niet achteraf worden ingebouwd.
Het Cisco Deep Network-model is afgestemd en getraind voor deze realiteit. Het is een gespecialiseerd netwerkmodel dat is ontworpen om te denken als een deskundige operator. Tijdens de implementatie kan het worden gecombineerd met Analytics Context Engineering (ACE) en Lightweight Autonomous Program Synthesis and Execution (LAPSE), twee modelonafhankelijke innovaties die context- en machinegegevensbeheer schalen. Samen ondersteunen ze het redeneren op operatorniveau op ondernemingsniveau, waardoor snellere, op bewijs gebaseerde antwoorden worden geboden waarbij de context tijdens de diensten behouden blijft, zodat onderzoeken niet uitmonden in afkapping, lussen of giswerk.
Na het lezen van dit bericht zul je wetende wegstromen (1) wat is het Cisco Deep Network-model, (2) waarom generieke modellen moeite hebben met netwerkoperaties e (3) de twee innovaties die het op grote schaal praktisch maken: ACE en LAPSE.
Gestandaardiseerde LLM’s ondersteunen geen netwerkworkflows
Sjablonen voor algemene doeleinden zijn effectief bij het samenvatten, uitspreken en ophalen van algemene kennis. Netwerkoperaties leggen de nadruk op een andere reeks beperkingen.
De gegevens komen niet overeen. Zelfs bij routineonderzoek zijn lange tijdreeksen, talloze tellers, pakketverlies en latentie tussen locaties, grote configuratiesecties en logboeken van veel apparaten betrokken. Standaardmodellen bereiken snel contextlimieten en beginnen vervolgens informatie te laten vallen of te vertrouwen op snelkoppelingen.
Gemengde gegevens zijn beschadigd. Netwerken bestaat zelden alleen maar uit tekst. Dit zijn telemetrie, JSON, syslog, CLI-uitvoer, configuratiefragmenten en ticketcontext samen. Zelfs met grote contextvensters zijn veel grensmodellen geoptimaliseerd voor menselijke taal en niet voor machinegegevens, zodat ze de exacte tijdstempel, interface, beleid of metrische verandering die de hoofdoorzaak duidelijk maakt, uit het oog kunnen verliezen.
Het Cisco Deep Network-model gaat uit van een andere aanname: dwing het model niet om alles te lezen. Bouw in plaats daarvan een systeem dat machinegegevens op grote schaal kan verwerken, de onderzoekscontext kan behouden zonder u te belasten, en probleemoplossing benadert zoals een expert dat zou doen.
Wat is het Cisco Deep Network-model?
Het Cisco Deep Network-model is een speciaal gebouwd model voor netwerken, ontworpen om probleemoplossing, configuratie en automatisering met grotere precisie te ondersteunen dan generieke modellen. Het is niet de bedoeling om een betere chatbot te creëren. De bedoeling is om een model te creëren dat zich gedraagt als een deskundige netwerkoperator: op bewijs gebaseerd, gedisciplineerd in het oplossen van problemen en in staat om met duidelijke traceerbaarheid te convergeren naar de hoofdoorzaak en oplossing.
Benchmarkresultaten voor het Cisco Deep Network-model weerspiegelen deze specialisatie. Op een meerkeuzebenchmark in CCIE-stijlHet model van Cisco presteert tot 20% beter dan generieke modellen.
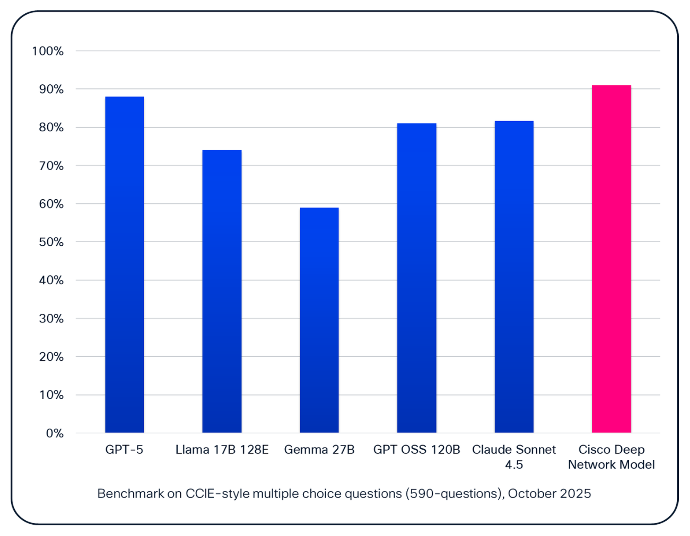
Op het eerste gezicht lijken sommige van deze verschillen misschien incrementeel. In de praktijk zijn ze dat niet. Zodra een model boven de 85% komt, zijn de resterende fouten vaak geconcentreerd in zeldzame, complexe randgevallen in plaats van in gewone modellen. Om de prestaties op dat niveau te verbeteren, moet de lange staart van netwerkscenario’s worden aangepakt die generieke modellen vaak niet kunnen vastleggen.
Een analogie is hier nuttig: elk extra punt boven die drempel is vergelijkbaar met een topsporter die een paar fracties van een seconde van zijn wereldrecord scheert. De inspanning neemt dramatisch toe naarmate het werk verschuift van het verbeteren van algemene vaardigheden naar het oplossen van moeilijkere en minder frequente gevallen. Dit is waar branchespecifieke training, deskundig toezicht en operationele voorbereiding een aanzienlijk verschil maken.
Betrouwbare training en continu leren
Het model is gebaseerd op Cisco U-cursussen en kennis op CCIE-niveau die meer dan 40 jaar operationele ervaring vertegenwoordigen. Het model werd getraind op bijna 100 miljoen tokens, en Cisco-experts zorgden voor duizenden redeneringssporen, waarbij elk logicaniveau nauwgezet werd geannoteerd en gevalideerd, zodat het model niet alleen het antwoord leert, maar ook het pad op operatorniveau om daar te komen.
Netwerken evolueren ook voortdurend, en het Cisco Deep Network-model is ontworpen om met hen mee te evolueren. Door middel van versterkend leren past het zich aan met behulp van nieuwe, niet-openbare, real-world gegevens en informatie van het Technical Assistance Center (TAC) en Customer Experience (CX) die alleen beschikbaar zijn binnen Cisco, zodat het model verbetert naarmate operationele modellen, software en omgevingen veranderen.
LLM-prestatieoptimalisatie voor machinegegevens: ACE en LAPSE
Het Cisco Deep Network-model is meer dan een getraind model. Het wordt geleverd als een systeem dat domeinredenering combineert met contextbeheer en machinegegevensuitvoering, gebouwd om de twee beperkingen te overwinnen die de meeste implementaties doorbreken: (1) contextschaal e (2) schaal van machinegegevens.
Analytische Context Engineering (ACE)

ACE transformeert een compacte prompt in compacte canonieke weergaven en reconstrueert deze met zo min mogelijk tokens. Het doel is niet een samenvatting waarin details worden weggegooid. Het doel is om het aantal tokens dat LLM moet verwerken te verminderen zonder datgene verloren te gaan, zodat de context behouden kan blijven tijdens data-intensieve multi-round onderzoeken en de taakprompt binnen het contextvenster van het model kan blijven. In de praktijk betekent dit het normaliseren van gemengde invoer, zoals telemetriesamenvattingen, logfragmenten, configuratiedelta’s en ticketnotities, in een consistent onderzoeksrecord dat in de loop van de tijd bruikbaar blijft.
Dit is belangrijk omdat het aantal onderzoeken natuurlijk enorm groeit. Elke wending voegt herhaalde geschiedenis, gedeeltelijke artefacten, bewijsmateriaal in gemengd formaat en concurrerende hypothesen toe. Na verloop van tijd kan zelfs een correct model minder betrouwbaar worden omdat de input minder bruikbaar wordt. ACE is ontworpen om het onderzoek compact, stabiel en trouw aan het onderliggende bewijsmateriaal te houden.
Cisco meldt dat ACE de grootte van prompts met ongeveer 20-90% kan verkleinen, waarbij de informatie behouden blijft die het model nodig heeft om accuraat te blijven. Gestandaardiseerde benaderingen slagen er doorgaans slechts in om ongeveer 0 tot 30% te verminderen voordat kritische details beginnen af te nemen. In praktische termen is dit wat het werk in meerdere bochten consistent houdt in plaats van broos.
Wilt u de technische details achter Analytics Context Engineering? Deze blog gaat dieper.
Lichtgewicht synthese en uitvoering van zelfstandige programma’s (LAPSE)

LAPSE hanteert een andere benadering van schaalgrootte. Wanneer de invoer uit grote machinegegevens bestaat, creëert en voert het systeem op verzoek tools uit om de gegevens van een bronschema om te zetten in een doelschema dat voor de taak is geoptimaliseerd. Het model ontvangt taakklare uitvoer in plaats van onbewerkte telemetriedumps, waardoor de workflow snel blijft en het risico op het missen van kritieke signalen wordt verkleind.
Dit is een pragmatische ontwerpkeuze. Tijdreeksen en telemetrie met hoog volume kunnen het beste worden afgehandeld met tools die aggregeren, filteren, opnieuw vormgeven en verwerken. Het model moet een leidraad zijn voor wat er moet worden berekend en hoe het moet worden geïnterpreteerd, en mag niet zelf als rekenmachine fungeren.
Met LAPSE kan het model vrijwel onbeperkte machinegegevens verwerken, waardoor de verwerking van machinegegevens voor interactieve operationele taken wordt versneld en ruwe telemetrie wordt omgezet in gestructureerde, taakklare gegevens. Gerapporteerde vergelijkingen laten een latentie van ongeveer 3-5 seconden zien (vergeleken met 27-200 seconden voor standaardoplossingen) voor taken zoals transformatie van machinegegevensschema’s. De gerapporteerde transformatienauwkeurigheid bedraagt bijna 100% (vergeleken met 0-70%).
Het punt voor besluitvormers is eenvoudig. Dat is het verschil tussen een AI-systeem dat een operator kan bijhouden en een systeem dat van elk onderzoek een wachtspel maakt.
Hoe het in de praktijk werkt
ACE en LAPSE zijn qua ontwerp complementair.
- LAPSE verwerkt het zware werk van het transformeren van machinegegevens snel en deterministisch.
- ACE houdt de onderzoeksstatus compact, stabiel en inzetbaar bij meerploegendienst.
Samen maken ze een workflow mogelijk die moeilijk te handhaven is voor algemene systemen: (1) begin met opzet, (2) het minimale relevante bewijsmateriaal verzamelen, (3) consistent bijhouden van wat bekend is, bijv (4) snel genoeg resultaten opleveren en voldoende gefundeerd zijn zodat u vertrouwen kunt hebben in de productie.
Het model ondersteunt ook een ‘next best action’-probleemoplossingscyclus, zodat onderzoeken verlopen als het werk van een expert: hypotheses opstellen, testen, verfijnen en convergeren naar de hoofdoorzaak.
Tot leven gebracht in Cisco-producten
Het komt tot leven via de Cisco AI-producten die operators dagelijks gebruiken. In Cisco AI Canvas helpt het teams meerdere domeinen te onderzoeken met een consistente registratie van bewijsmateriaal, gestructureerde output te genereren uit grote telemetrie en sneller van verdenking naar gevalideerde hoofdoorzaak te gaan. In Cisco AI Assistant-ervaringen transformeert het natuurlijke taalintenties in redeneringen op operatorniveau en bruikbare volgende stappen, gebaseerd op de telemetrie en context die beschikbaar zijn voor de gebruiker.
Wat is er echt anders
Veel leveranciers beweren dat AI nuttig is voor netwerken. Het Cisco Deep Network-model verschilt op basis van specifieke operationele eigenschappen.
- Gerichte training en deskundige monitoring voor netwerknauwkeurigheid
- Engineering van de schaalbaarheid van machinegegevens door de synthese en lichtgewicht uitvoering van autonome programma’s
- Verliesloze contextoptimalisatie voor lange onderzoeken via Analytics Context Engineering
&#
BRON
Paul Arends
“Ik ben Paul Arends, afgestudeerd in Bedrijfskunde aan de Universidad Complutense en met een master in Personeelsmanagement en Organisatieontwikkeling aan ESIC. Ik ben geïnteresseerd in netwerken en social media en richt mijn professionele ontwikkeling op talentmanagement en organisatieverandering.”
 Paul Arends
Paul Arends- Cisco
- februari 6, 2026
- 4 views
Het Dream Team bereidt zich voor op Super Bowl LX.
De Super Bowl LX staat op het punt een van de grootste Amerikaanse sportevenementen van het jaar te worden. Meer dan 70.000 fans zullen naar het Levi’s® Stadium komen en…

- Paul Arends
- Cisco
- februari 6, 2026
- 6 views
AIUC-1 implementeert Cisco’s AI-beveiligingsframework
Deze blog is mede geschreven door Amy Chang, Hyrum Anderson, Rajiv Dattani en Rune Kvist. We zijn verheugd om Cisco aan te kondigen als technisch medewerker AIUC-1. De standaard zal…





