Naarmate het gebruik van kunstmatige intelligentie blijft groeien – van het samenvatten van documenten tot gepersonaliseerde software-agenten – zoeken ontwikkelaars en fans naar snellere manieren om grote taalmodellen (LLM) uit te voeren. Lokale uitvoering van modellen op een pc met NVIDIA GeForce RTX GPU maakt het mogelijk om hoogwaardige inferentie uit te voeren, verbetert de gegevensprivacy en biedt volledige controle over de distributie en integratie van kunstmatige intelligentie. Tools zoals LM Studio – gratis – maken dit mogelijk en bieden gebruikers een eenvoudige manier om LLM op hun hardware te verkennen en te bouwen.
LM Studio is een van de meest gebruikte tools geworden voor lokale LLM-inferenties. Gebouwd op de uitvoering van high-performance lama.cpp, stelt de app de modellen in staat om volledig offline te functioneren en kan ook fungeren als een eindpunt van de programmeerinterface van de OpenAI-compatibele applicatie (bijen) voor integratie in gepersonaliseerde workflows.
De release van LM Studio 0.3.15 biedt verbeterde prestaties voor RTX GPU dankzij CUDA 12.8, waardoor de belasting van het model en de responstijden aanzienlijk worden verbeterd. De update introduceert ook nieuwe functies gericht op ontwikkelaars, waaronder een verbeterd gebruik van de tool via de “Tool_Choice Parameter” en een opnieuw ontworpen systeemprompteditor.
De nieuwste verbeteringen in LM Studio verbeteren zijn prestaties en bruikbaarheid en bieden de hoogste doorvoer op RTX-pc’s. Dit betekent snellere antwoorden, meer interacties en betere tools voor de bouw en integratie van kunstmatige intelligentie op lokaal niveau.
Waar alledaagse apps AI-versnelling ontmoeten
LM Studio is gebouwd voor flexibiliteit, geschikt voor zowel willekeurige experimenten als volledige integratie in gepersonaliseerde workflows. Gebruikers kunnen interageren met modellen via een desktop-chatinterface of de ontwikkelaarsmodus inschakelen om een eindpunt-API te dienen die compatibel is met OpenAI. Dit vereenvoudigt de lokale LLM-verbinding met workflows in apps zoals codeversus of op maat gemaakte desktopagenten.
LM Studio kan bijvoorbeeld worden geïntegreerd met Obsidian, een populaire kennisbeheer-app op basis van markdown. Met behulp van plug-ins ontwikkeld door de community, zoals de tekstgenerator en intelligente verbindingen, kunnen gebruikers inhoud genereren, het onderzoek samenvatten en hun notities ondervragen, allemaal gevoed door lokale LLM’s die LM Studio uitvoeren. Deze plug-in verbindt rechtstreeks met de lokale LM Studio-server, waardoor interacties snel kunnen worden uitgevoerd zonder op de cloud te vertrouwen.
De update van 0.3.15 voegt functies toe voor ontwikkelaars, waaronder een grotere controle over het gebruik van de tool via de “Tool_Choice” en een bijgewerkte systeemprompteditor voor het beheer van langere of complexere instructies.
Met de Tool_Choice-parameter kunnen ontwikkelaars controleren hoe de modellen zich inzetten voor externe tools, waardoor een gereedschapsgesprek wordt afgedwongen, volledig wordt uitgeschakeld of het model dynamisch kan beslissen. Deze grotere flexibiliteit is met name waardevol voor de constructie van gestructureerde interacties, generatieworkflows of pijplijnen. Samen verbeteren deze updates zowel de experimentele als productiegevallen voor ontwikkelaars die bouwen met LLM.
LM Studio ondersteunt een breed scala aan open-source modellen zoals Gemma, LLAMA 3, Mistral en Orca, evenals een verscheidenheid aan kwantisatieformaten, van 4 bits tot volledige precisie.
Veelvoorkomende toepassingen omvatten multi-turn chat met lange contextvensters, vraag-en-antwoord op basis van documenten en pijplijnen van lokale agenten. Met het gebruik van een lokale inferentieserver aangedreven door de geoptimaliseerde RTX NVIDIA-lama.cpp-softwarebibliotheek, kunnen gebruikers eenvoudig lokale LLM integreren op RTX-pc’s.
Of het nu gaat om het optimaliseren van de efficiëntie op een compact RTX-aangedreven systeem of om de doorvoer te maximaliseren op een high-performance desktop, LM Studio biedt volledige controle, snelheid en privacy, allemaal op RTX.
Testen van maximale doorvoer op RTX GPU
In het hart van de versnelling van LM Studio staat LLAMA.CPP, een open-source runtime ontworpen voor efficiënte inferentie op consumentenhardware. Nvidia heeft samengewerkt met de LM Studio- en LLAMA.CPP-gemeenschappen om verschillende verbeteringen te integreren om de prestaties van de RTX GPU te maximaliseren.
Belangrijke optimalisaties zijn onder andere:
- CUDA-grafiek Enablement: Hiermee kunnen meerdere GPU-bewerkingen worden gegroepeerd in één enkele CPU-oproep, waardoor de algehele CPU-kosten worden verlaagd en de modelprestaties tot 35% worden verbeterd.
- Flash Attention Kernels of Attention: Verhoogt de doorvoer met maximaal 15% door de manier te verbeteren waarop LLM’s aandacht besteden – een kritieke operatie in transformermodellen. Deze optimalisatie maakt langere contextvensters mogelijk zonder de geheugen- of berekeningsvereisten te vergroten.
- Ondersteuning voor de nieuwste RTX-architecturen: De update van LM Studio naar CUDA 12.8 garandeert compatibiliteit met het hele scala van pc’s tot de RTX-Dalla GeForce RTX 20 tot de NVIDIA Blackwell Class GPU’s, waardoor gebruikers de flexibiliteit hebben om hun workflows aan te passen aan high-end desktoplaptops.

Met een compatibel stuurprogramma wordt LM Studio automatisch bijgewerkt naar runtime CUDA 12.8, waardoor aanzienlijk snellere modelbelastingstijden en hogere algehele prestaties mogelijk zijn.
Deze verbeteringen bieden vloeiendere inferentie en snellere responstijden over het hele spectrum van RTX-DAI dunne en lichte laptops tot krachtige desktops en werkstations.
Aan de slag met LM Studio
LM Studio is gratis te downloaden en te gebruiken op Windows, MacOS en Linux. Met de nieuwste versie 0.3.15 en lopende optimalisaties kunnen gebruikers voortdurende verbeteringen in prestaties, aanpassing en bruikbaarheid verwachten, waardoor lokale kunstmatige intelligentie sneller, flexibeler en toegankelijker wordt.
Gebruikers kunnen een model laden via de desktop-chatinterface of de ontwikkelaarsmodus inschakelen om een API te bedienen die compatibel is met OpenAI.
Download de nieuwste versie van LM Studio en open de applicatie om snel aan de slag te gaan.
- Klik op het vergrootglaspictogram in het linkerpaneel om het Ontdekken menu te openen.
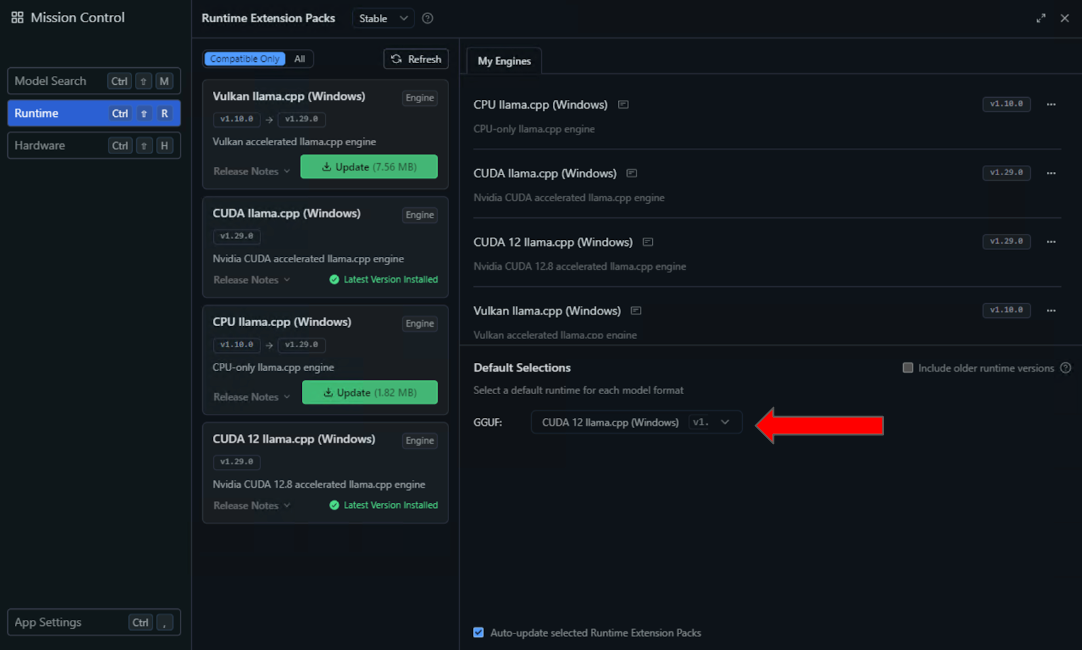
- Selecteer de Looptijd instellingen in het linkerpaneel en zoek naar de CUDA 12 LLAMA.CPP (Windows) Runtime in de lijst met beschikbare opties. Selecteer de knop om te downloaden en te installeren.

- Configureer LM Studio na installatie om deze runtime standaard te gebruiken door CUDA 12 LLAMA.CPP (Windows) te selecteren in de vervolgkeuzelijst met standaardinstellingen.
- Voor de nieuwste stappen in de optimalisatie van de CUDA-uitvoering, laadt u een model in LM Studio en ga naar het instellingenmenu door te klikken op het tandwielicoon links van het geladen model.

- Vanuit het resulterende vervolgkeuzemenu, activeer “flash care” om alle niveaus van het model op de GPU te downloaden door de “Offload GPU” cursor naar rechts te slepen.

Zodra deze functies zijn ingeschakeld en geconfigureerd, is de uitvoering van NVIDIA GPU-inferentie op een lokale configuratie optimaal.
LM Studio ondersteunt modelvoorinstellingen, een reeks kwantisatieformaten en ontwikkelaarsbedieningselementen zoals Tool_Choice voor nauwkeurige inferentie. Voor degenen die willen bijdragen, wordt het LLAMA.CPP GitHub-repository actief onderhouden en blijft het evolueren met prestatieverbeteringen geleid door de community en Nvidia.
Elke week biedt de serie Garage RTX-blogs AI-innovaties en inhoud op basis van communityfeedback voor degenen die meer willen weten over de mogelijkheden van Nvidia NIM en kunstmatige intelligentieprojecten, evenals voor het bouwen van AI-agenten, creatieve workflows, digitale personages, productiviteitsapps en meer op basis van AI op pc’s.
Verbind met NVIDIA op Facebook, Instagram, TikTok en LinkedIn en blijf op de hoogte door je te abonneren op de RTX-nieuwsbrief.
Volg NVIDIA Workstation op LinkedIn en Twitter.




