Grote modellen (LLM), getraind op gegevenssets met miljarden tokens, kunnen inhoud van hoge kwaliteit genereren. Ze vormen de basis voor veel van de meest populaire toepassingen van kunstmatige intelligentie, waaronder chatbots, assistenten, codegeneratoren en nog veel meer.
Een van de meest toegankelijke manieren om vandaag met LLM’s te werken, is met alles wat LM, een desktop-applicatie gebouwd voor enthousiastelingen die een alles-in-één kunstmatige intelligentie-assistent willen die rechtstreeks op privacy op uw pc is gericht.
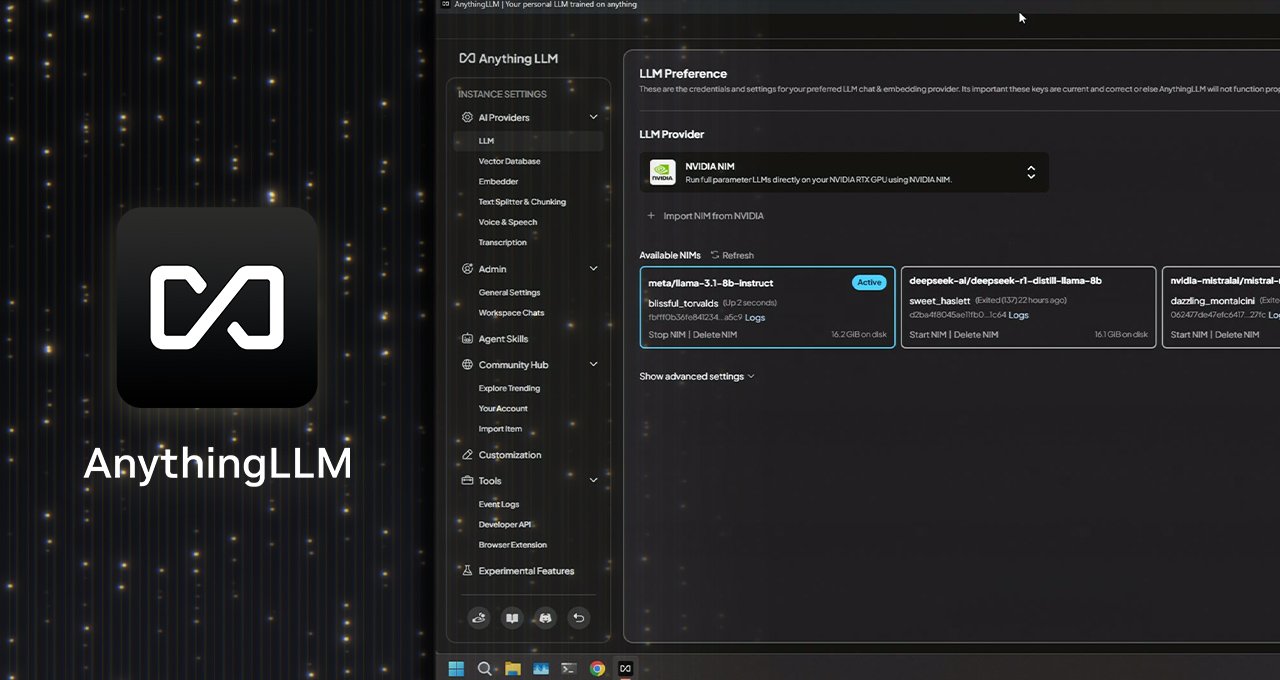
Met de nieuwe ondersteuning voor de microservices van NIM NIM op NVIDIA GeForce RTX en NVIDIA RTX Pro GPU, kunnen gebruikers nog snellere prestaties behalen voor meer reactieve lokale werkstromen.
Wat is iets dilm?
Wat een alles-in-één applicatie is waarmee gebruikers lokale LLM’s, Generatiesystemen (RAG) en Agents-tools kunnen uitvoeren.
Het fungeert als een brug tussen de favoriete LLM’s van een gebruiker en hun gegevens en biedt toegang tot de tools (vaardigheden genoemd) waarmee het gebruik van LLM wordt toegepast voor specifieke activiteiten zoals:
- Antwoord op vragen: Krijg antwoorden op de beste LLM-vragen – zoals LLAMA en Deepseek R1 – zonder kosten.
- Persoonlijke gegevensquery: Gebruik RAG voor vragen over privé-inhoud, waaronder PDF’s, woorden, codebases en meer.
- Samenvatting van documenten: Genereer samenvattingen van lange documenten, zoals onderzoeksdocumenten.
- Gegevensanalyse: Diepgaande analyses maken op basis van gegevens door bestanden te laden en te bevragen met LLM’s.
- Acties ondernemen: Dynamisch zoeken naar inhoud met behulp van lokale of externe bronnen, het uitvoeren van generatieve tools en acties op basis van gebruikersinstructies.
De applicatie kan ook verbinding maken met een breed scala aan lokale LLM’s – open source, evenals grotere LLM’s in de cloud, waaronder die van Openai, Microsoft en Anthropic. Bovendien biedt de applicatie toegang tot vaardigheden om de functionaliteit uit te breiden naar agenten via zijn communityhub.
Met een installatie met één klik en de mogelijkheid om te lanceren als een zelfstandige app of uitbreiding van de browser-extensie in een intuïtieve ervaring zonder ingewikkelde configuratie, is het een uitstekende optie voor AI-enthousiastelingen, vooral die met GPU-systemen.
RTX voedt elke versnelling
GeForce RTX en NVIDIA RTX PRO GPU bieden aanzienlijke prestatieverbeteringen voor de uitvoering van LLM’s en agenten in alles, waardoor de inferentie met tensorkernen wordt versneld die zijn ontworpen om de AI te versnellen.
Ollama beheert LLM’s voor uitvoering op versnelde apparaten via de LLM.CPP en GGML TENSOR BOOKTORREN VOOR AUTOMATISCH LEREN.
Ollama, Lama.CPP en GGML zijn geoptimaliseerd voor de NVIDIA RTX GPU en de Tensor-kernen van de vijfde generatie. De prestaties op GeForce RTX 5090 zijn 2,4x hoger in vergelijking met een Ultra Apple M3.
Terwijl NVIDIA nieuwe NIM-microservices en referentiewerkstromen toevoegt – zoals de groeiende bibliotheek van kunstmatige intelligentieprojecten – die tools zoals elke LM ontgrendelen voor nog meer multimodale toepassingen van kunstmatige intelligentie.
Wat dan ook – nu met NVIDIA NIM
Wat onlangs ondersteuning heeft toegevoegd voor NIM NIM NVIDIA MODELLE MICROSERVICES aan generaties die zijn geoptimaliseerd voor prestaties en voorverpakte workflows om gemakkelijk te beginnen met werkstromen naar de RTX op pc met een vereenvoudigde FIPI.
NVIDIA NIM’s zijn geweldig voor ontwikkelaars die snel een generatief model in een workflow willen testen. In plaats van het juiste model te moeten vinden, alle bestanden te downloaden en te begrijpen hoe alles moet worden verbonden, biedt het een enkele container met alles wat je nodig hebt. En ze kunnen zowel op de cloud als op de pc werken, waardoor het eenvoudig is om een prototype op lokaal niveau te maken en vervolgens te distribueren naar de cloud.
Door ze aan te bieden in de intuïtieve gebruikersinterface van alles, hebben gebruikers een snelle manier om ze te testen en te ervaren. Vervolgens kunnen ze ze aansluiten op hun werkstromen met alles wat LM is, of profiteren van de NVIDIA AI-projecten en de NIM-documentatie en voorbeeldcode om ze rechtstreeks te integreren in hun apps of projecten.
Ontdek de diverse NIM-microservices die beschikbaar zijn om kunstmatige intelligentie-workflows te verbeteren, waaronder taal- en beeldgeneratie, kunstmatige visie en spraakverwerking.
Elke week presenteert de RTX naar garages blogserie innovaties en content aan de community voor degenen die meer willen weten over NIM Microservices en kunstmatige intelligentieprojecten, evenals het bouwen van creatieve AI-workflows, digitale assistenten, productiviteits-apps en meer op pc’s en werkstations met AI.
Verbind met NVIDIA op pc’s via Facebook, Instagram, Tiktok en meer en blijf op de hoogte door je aan te melden voor de RTX-nieuwsbrief op pc’s.
Volg NVIDIA Workstation op LinkedIn en meer en blijf op de hoogte van softwareproductinformatie.
. Niet verzinnen. Schrijf niet in een andere taal. Bespreek niet de auteur van de inhoud. Richt je op de inhoud, niet op andere pagina’s, zoals privacybeleid, cookiebeleid of andere. Wees uitgebreid met herschrijven: minimaal 300 woorden. Vertaal geen merken, producten of bedrijfsnamen. Ik ben van plan om morgen naar de stad te gaan en een paar boodschappen te doen.https://www.youtube.com/watch?v=Q7EZJUPNBA4https://www.youtube.com/watch?v=k_mnb6rrlha
BRON





