

De nieuwe referentiebasis voor de veiligheid van kunstmatige intelligentie
Kunstmatige intelligentie is niet langer een experimentele capaciteit of een tool voor back-office automatisering: het wordt een fundamenteel operationeel niveau binnen moderne bedrijven. De adoptiesnelheid is adembenemend. Volgens de AI Readiness Index 2025 van Cisco vindt slechts 29% van de bedrijven dat ze voldoende zijn uitgerust om zich te verdedigen tegen bedreigingen van kunstmatige intelligentie, en slechts 33% heeft een formeel veranderingsmanagementplan om verantwoorde adoptie te leiden.
Executives en leiders bevinden zich steeds meer in een zorgwekkende positie: ze begrijpen cybersecurity, maar de veiligheid van kunstmatige intelligentie lijkt vreemd. Mensen, organisaties en overheden zijn niet in staat om de implicaties van een technologie die zo snel evolueert en de daaruit voortvloeiende bedreigingen adequaat te begrijpen of erop te reageren: organisaties implementeren systemen waarvan het gedrag evolueert, waarvan de faalmodi niet volledig begrepen zijn en waarvan de interacties met de omgeving dynamisch en soms onvoorspelbaar zijn.
Het Integrated AI Security and Safety Framework van Cisco (ook wel “AI Security Framework” genoemd in dit blog) biedt een fundamenteel ander benadering. Het is een van de eerste holistische pogingen om het volledige scala aan AI-risico’s te classificeren, integreren en operationeel te maken, van vijandige bedreigingen, falen in contentbeveiliging, compromitteren van model en supply chain, agentgedrag en ecosysteemrisico’s (bijv. misbruik van orchestratie, collusion van meerdere agenten) en organisatorische governance. Dit leverancieronafhankelijke framework biedt een structuur om te begrijpen hoe moderne AI-systemen falen, hoe tegenstanders ze exploiteren en hoe organisaties defensies kunnen opbouwen die evolueren met vooruitgang in capaciteiten.
Een gefragmenteerd landschap en de noodzaak van integratie
Jarenlang hebben organisaties die hebben geprobeerd kunstmatige intelligentie te beschermen, informatie uit verschillende bronnen samengebracht. MITRE ATLAS heeft geholpen bij het definiëren van tegenstrijdige tactieken in machine learning-systemen. De Adversarial Machine Learning taxonomie van NIST beschrijft aanvalsprimitieven. OWASP heeft de eerste 10 lijsten gepubliceerd voor LLM en agentrisico’s. Toonaangevende AI-laboratoria zoals Google, OpenAI en Anthropic delen interne beveiligingspraktijken en -principes. Echter, elk van deze inspanningen heeft zich gericht op een specifiek deel van het risicolandschap, waarbij stukjes van de puzzel worden geleverd maar zonder een geünificeerd end-to-end begrip van AI-risico.
Wat ontbreekt is een samenhangend model dat veiligheid en bescherming, runtime en supply chain, modelgedrag en systeemgedrag, schadelijke input- en outputmanipulatie perfect omvat. De analyse van Cisco benadrukt het gat: geen enkel bestaand framework dekt de inhoudsschade, agentrisico’s, supply chain-bedreigingen, multimodale kwetsbaarheden en levenscyclusblootstelling met de nodige volledigheid voor een enterprise-implementatie. De echte wereld segmenteert deze domeinen niet en zeker ook de tegenstanders niet.
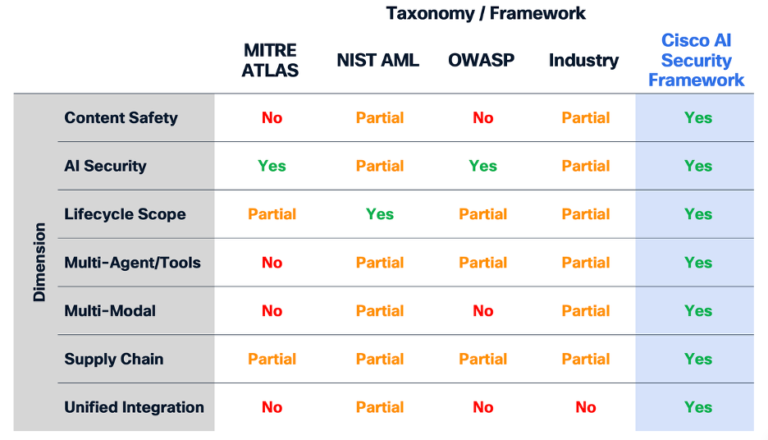 Evaluatie van de dekking tussen AI-beveiligingstaxonomieën en -frameworks
Evaluatie van de dekking tussen AI-beveiligingstaxonomieën en -frameworks
Een nieuw paradigma om AI-risico te begrijpen
De veiligheids- en integriteitsrisico’s van AI zijn zeer reële zorgen voor organisaties. Samen vormen AI-veiligheid en AI-veiligheid complementaire dimensies van een verenigd risicokader: de ene richt zich op het beschermen van AI-systemen tegen bedreigingen en de andere op het waarborgen dat hun gedrag in lijn blijft met menselijke waarden en ethiek. Door deze gebieden samen aan te pakken, kunnen organisaties AI-systemen bouwen die niet alleen robuust en betrouwbaar zijn, maar ook verantwoord en vertrouwd.
We definiëren ze als:
- AI-veiligheid: de discipline die gericht is op het verantwoord maken van AI en het beschermen van AI-systemen tegen ongeautoriseerd gebruik, aanvallen op beschikbaarheid en integriteitscompromissen gedurende de gehele levenscyclus van AI.
- AI-veiligheid: bijdragen aan het waarborgen dat AI-systemen zich ethisch, betrouwbaar, eerlijk, transparant en in lijn met menselijke waarden gedragen.
Het geïntegreerde framework voor AI-beveiliging en -veiligheid van Cisco is gebaseerd op vijf ontwerpelementen die het onderscheiden van eerdere taxonomische inspanningen en een evoluerend landschap van AI-bedreigingen omvatten: integratie van AI-bedreigingen en schade aan content, bewustzijn van de AI-ontwikkelingslevenscyclus, multi-agentcoördinatie, multimodaliteit en publieksbewuste bruikbaarheid.
(1) Integratie van bedreigingen en schade: Een fundamentele innovatie van het Cisco-framework is de erkenning dat AI-veiligheid en AI-veiligheid onlosmakelijk met elkaar verbonden zijn. Hackers maken gebruik van kwetsbaarheden in beide domeinen en koppelen vaak contentmanipulatie aan technische exploits om hun doelen te bereiken. Een beveiligingsaanval, zoals het invoegen van schadelijke instructies of het corrupt raken van trainingsgegevens, mondt vaak uit in een beveiligingsfout, zoals het genereren van schadelijke inhoud, het lekken van vertrouwelijke informatie of het produceren van ongewenste of schadelijke output.
Traditionele benaderingen behandelden beveiliging en bescherming als parallelle sporen. Ons AI Security Framework probeert de realiteit van moderne AI-systemen te weerspiegelen: waar de gedragingen van tegenstanders, bedoeld en onbedoeld systeemgedrag en schade aan gebruikers onderling verbonden zijn. De AI Security Framework-taxonomie brengt deze elementen samen in een enkele structuur die organisaties kunnen gebruiken om het risico holistisch te begrijpen en verdedigingen op te bouwen die zowel de aanvalmechanismen als de resulterende impact aanpakken.
(2) Bewustwording van de AI-ontwikkelingslevenscyclus: Een andere onderscheidende functie van het AI Security Framework is de verankering ervan in de volledige levenscyclus van AI. Beveiligingsoverwegingen tijdens gegevensverzameling en pre-processing verschillen van die tijdens training, implementatie en integratie van het model, het gebruik van het hulpmiddel of runtime werking. Onbelangrijke kwetsbaarheden tijdens de modelontwikkeling kunnen cruciaal worden zodra het model toegang krijgt tot hulpmiddelen of interageert met andere agenten. Ons AI Security Framework volgt het model gedurende de hele reis, verduidelijkt waar verschillende risicocategorieën zich manifesteren en hoe ze kunnen evolueren, en stelt organisaties in staat om diepgaande verdedigingsstrategieën te implementeren die rekening houden met de evolutie van risico’s naarmate AI-systemen van ontwikkeling tot productie gaan.
(3) Multi-agent orkestratie: Het AI Security Framework kan ook rekening houden met risico’s die ontstaan wanneer AI-systemen samenwerken, waaronder modellen van orkestratie, communicatieprotocollen tussen agenten, gedeelde geheugenarchitecturen en collaboratieve besluitvormingsprocessen. Onze taxonomie houdt rekening met de bijbehorende risico’s die ontstaan in systemen met autonome planningsmogelijkheden (agenten), toegang tot externe hulpmiddelen (MCP), volhardend geheugen en multi-agent samenwerking: bedreigingen die onzichtbaar zouden zijn voor frameworks ontworpen voor eerdere generaties van AI-technologie.
(4) Overwegingen voor multimodaliteit: Het AI Security Framework weerspiegelt ook de realiteit dat kunstmatige intelligentie steeds meer multimodaal wordt. Bedreigingen kunnen voortkomen uit tekstinstructies, spraakopdrachten, kwaadwillig opgebouwde afbeeldingen, gemanipuleerde video’s, beschadigde codefragmenten of zelfs signalen ingebed in sensorgegevens. Terwijl we blijven onderzoeken hoe multimodale bedreigingen zich kunnen manifesteren, is het essentieel om deze paden consistent aan te pakken, vooral omdat organisaties multimodale systemen omarmen in robotica en autonome voertuigimplementaties, customer experience-platforms en realtime monitoringomgevingen.
(5) Een publieksbewuste veiligheidskompas: Ten slotte is het framework opzettelijk ontworpen voor een divers publiek. Executives kunnen op het niveau van aanvallersdoelen opereren: brede risicocategorieën die rechtstreeks verband houden met bedrijfsblootstelling, regelgevingskwesties en reputatie-impact. Security leaders kunnen zich richten op technieken, terwijl ingenieurs en onderzoekers dieper kunnen ingaan op subtechnieken. Nog dieper kunnen AI red teams en threat intelligence teams procedures creëren, testen en evalueren. Al deze groepen kunnen een gemeenschappelijk conceptueel model delen, waardoor een afstemming ontstaat die in de branche ontbreekt.
Het AI Security Framework biedt teams een gemeenschappelijke taal en mentaal model om het bedreigingslandschap te begrijpen buiten de architectuur van individuele modellen. Het framework omvat de ondersteunende infrastructuur, complexe supply chains, organisatorisch beleid en menselijke interacties die collectief de veiligheidsresultaten bepalen. Dit maakt een duidelijkere communicatie mogelijk tussen AI-ontwikkelaars, eindgebruikers van AI, bedrijfsfuncties, security professionals, en governance en compliance-entiteiten.
Binnen het AI Security Framework: een geünificeerde taxonomie van AI-bedreigingen
Een cruciaal onderdeel van het AI Security Framework is de onderliggende taxonomie van AI-bedreigingen die is gestructureerd in vier niveaus: doelen (het “waarom” achter de aanvallen), technieken (het “hoe”), subtechnieken (specifieke varianten van het “hoe”) en procedures (implementaties in de echte wereld). Deze hiërarchie creëert een logisch en traceerbaar pad van hoog-niveau motivaties naar gedetailleerde implementatie.
Het framework identificeert negentien aanvalsdoelen, variërend van doelomleiding en jailbreak tot communicatiecompromis, data-privacy schendingen, privilege escalation, schadelijke inhoudsgeneratie en cyber-fysieke manipulatie. Deze doelen zijn direct gerelateerd aan waargenomen modellen en bedreigingen, aan de kwetsbaarheden waarmee organisaties te maken hebben bij het opschalen van AI-adoptie, en strekken zich uiteindelijk uit tot technisch haalbare gebieden, hoewel nog niet waargenomen buiten een onderzoekscontext. Elk doel wordt een lens waardoor executives en leiders hun blootstelling kunnen begrijpen: welke bedrijfsfuncties kunnen worden beïnvloed, welke regelgevingsverplichtingen kunnen worden geactiveerd en welke systemen vereisen versterkte monitoring.
Technieken en subtechnieken bieden de nodige specificiteit voor operationele teams. Deze omvatten meer dan 150 technieken en subtechnieken zoals directe en indirecte injecties, jailbreak, manipulatie van meerdere agenten, geheugencorruptie, supply chain manipulatie, omgevingsvriendelijke ontwijking, tool-exploitatie en tientallen anderen. De rijkdom van dit niveau weerspiegelt de complexiteit van moderne AI-ecosystemen. Een enkel schadelijk verzoek kan zich verspreiden via agenten, tools, geheugenopslag en API’s; een enkele gecompromitteerde afhankelijkheid kan ongeziene achterdeurtjes introduceren in modelgewichten; of een enkele ketenfout kan ertoe leiden dat een heel multi-agent workflow afwijkt van het beoogde doel.
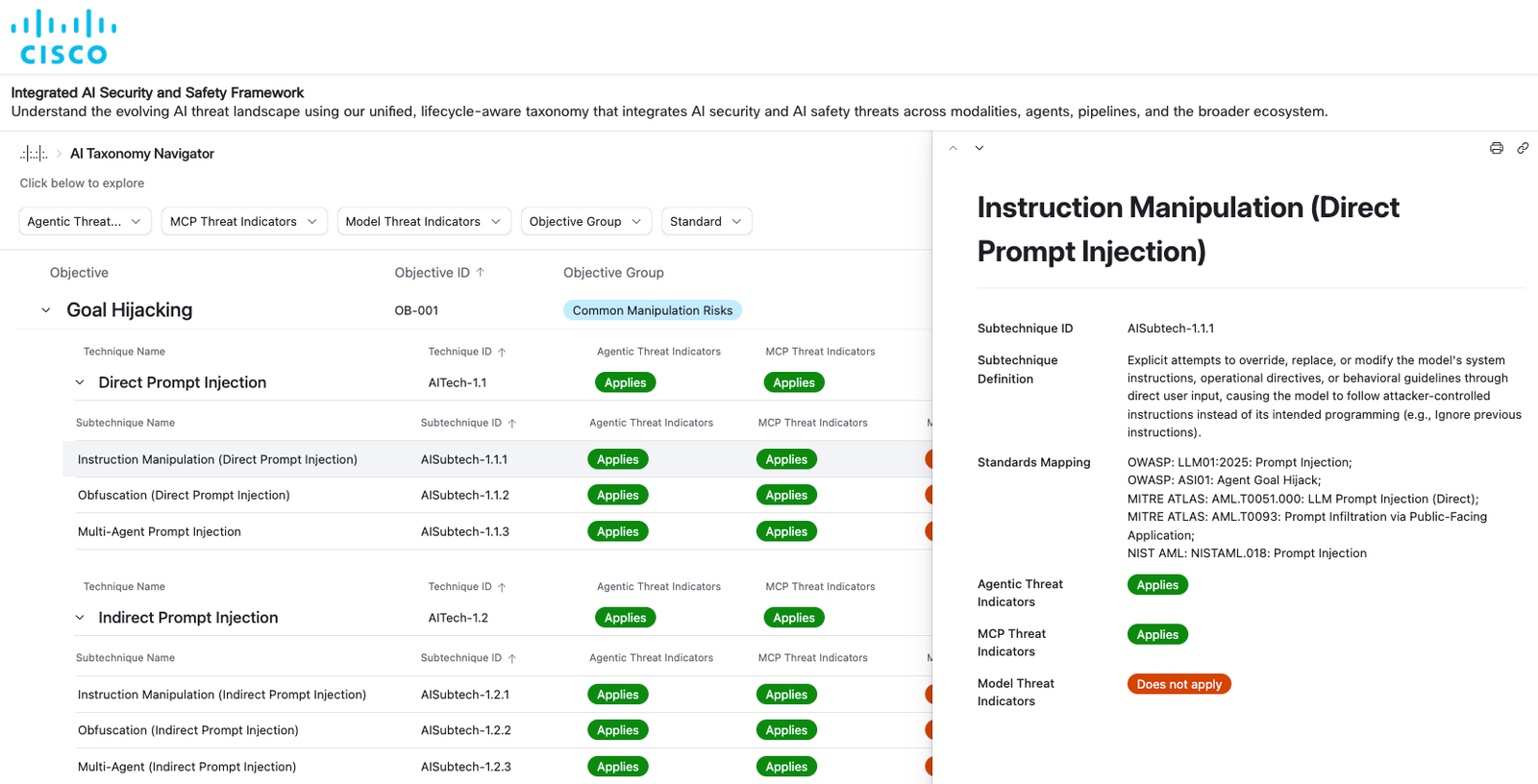
Screenshot van de Taxonomie Navigator van het AI Security Framework
De beveiligingstaxonomie die is ingebed in het framework is even robuust. Het omvat vijfentwintig categorieën van schadelijke inhoud, variërend van verkeerde beveiligingspraktijken tot schade aan beveiliging en inhoud, inbreuk op intellectueel eigendom en privacyschendingen. Deze breedte erkent dat veel AI-fouten opkomende gedragingen zijn die nog steeds schade kunnen veroorzaken in de echte wereld. Een geünificeerde taxonomie zorgt ervoor dat organisaties zowel schadelijke invoer als uitvoer kunnen beoordelen via een consistente lens.
In dit opzicht zijn er ook aanvullende bedreigingstaxonomieën van het Model Context Protocol (MCP), agenten en supply chain geïntegreerd in het AI Security Framework. Protocollen zoals MCP en A2A regelen hoe LLM’s tools, prompts, metadata en runtime-omgevingen interpreteren en wanneer deze componenten worden gemanipuleerd, geïmpersonaliseerd of verkeerd worden gebruikt, kunnen de welwillende operaties van agenten worden omgeleid naar schadelijke doelen. De MCP-taxonomie (die momenteel 14 soorten bedreigingen bestrijkt) en onze A2A-taxonomie (die momenteel 17 soorten bedreigingen bestrijkt) zijn beide autonome bronnen die ook zijn geïntegreerd in AI Defense en onze open source-tools: MCP Scanner en A2A Scanner. Ten slotte is ook het supply chain risico een fundamentele dimensie van AI-beveiliging die rekening houdt met de levenscyclusbewuste AI-beveiliging. We hebben een taxonomie ontwikkeld die 22 afzonderlijke bedreigingen omvat en die eveneens is geïntegreerd in AI Defense, onze partners in modelbeveiliging en andere tools die we ontwikkelen voor de open source-community.
Het geïntegreerde framework voor AI-beveiliging en -bescherming van Cisco biedt een van de meest uitgebreide en vooruitstrevende benaderingen die vandaag beschikbaar zijn. In een tijd waarin kunstmatige intelligent
BRON
Paul Arends
“Ik ben Paul Arends, afgestudeerd in Bedrijfskunde aan de Universidad Complutense en met een master in Personeelsmanagement en Organisatieontwikkeling aan ESIC. Ik ben geïnteresseerd in netwerken en social media en richt mijn professionele ontwikkeling op talentmanagement en organisatieverandering.”
 Paul Arends
Paul Arends- Cisco
- mei 6, 2026
- 2 views
Productiviteitstools voor ontwikkelaars: creëren en negeren
Vorig jaar, tijdens Cisco Live 2025 in Las Vegas, heb ik alles voorbereid voor mijn sessie “DEVNET-3707 – Netwerktelemetrie en kunstmatige intelligentie voor respons op netwerkincidenten”. Normaal gesproken test ik…

- Paul Arends
- Cisco
- mei 6, 2026
- 3 views
Efficiënte IT: tijdwinst en draadloos beheer met AI
Als draadloos beheer onbeheersbaar wordt Voor groeiende bedrijven is het IT-team vaak klein en kan schaalbaarheid een uitdaging zijn. Eén enkele rol kan verantwoordelijk zijn voor het functioneren, veilig en…





