

Als we praten over het bouwen van AI-datacenters, stelen de GPU-oost-west-stoffen vaak de show. Maar er is nog een even kritische verkeersroute: de noord-zuid connectiviteit. In de huidige AI-omgevingen kan de manier waarop jouw datacenter gegevens verwerft en op grote schaal resultaten levert, je AI-strategie maken of breken.
Waarom noord-zuid verkeer nu belangrijker is voor grootschalige kunstmatige intelligentie
Kunstmatige intelligentie is niet langer een geïsoleerd project, verborgen in een afgezonderd cluster. Bedrijven evolueren snel om kunstmatige intelligentie als een gedeelde service aan te bieden, waarbij enorme hoeveelheden gegevens worden verzameld van externe bronnen en resultaten worden geleverd aan gebruikers, applicaties en downstream systemen. Dit door AI gedreven verkeer genereert snelle en high-bandwidth noord-zuid stromen die kenmerkend zijn voor moderne AI-omgevingen:
- Input en voorverwerking van enorme datasets uit objectarchieven, datalakes of streamingplatforms
- Uploading en controleren van grote modellen vanuit een high-performance opslagruimte
- Queryen van vector databases en feature stores om context te bieden voor retrieval-augmented generation (RAG) en agent-based workflows
- Het leveren van real-time inferenties aan duizenden gelijktijdige gebruikers of microservices
AI-workloads versterken de traditionele noord-zuid-uitdagingen; ze komen vaak onverwacht, kunnen terabytes in enkele minuten verplaatsen en zijn zeer gevoelig voor latentie en jitter. Elke vertraging laat dure GPU’s ongebruikt en verlengt de jobvoltooiingstijden, verhoogt de kosten en vermindert het rendement op investeringen in kunstmatige intelligentie.
Het begrijpen van het AI-cluster: een multi-netwerk architectuur
Het is gemakkelijk om een AI-cluster voor te stellen als een enkel monolithisch netwerk. In werkelijkheid is het een samenstelling van verschillende onderling verbonden netwerken die samen moeten werken op een voorspelbare manier:
- Het front-end netwerk verbindt gebruikers, applicaties en services met het AI-cluster.
- Het opslagnetwerk biedt toegang tot high-throughput opslagruimte.
- Het back-end verwerkingsnetwerk transporteert verkeer van GPU naar GPU voor berekeningen.
- Out-of-band managementnetwerk voor baseboard management controllers (BMC’s), hostbeheer en toegang tot het controleplan.
- Datacenterstructuur, inclusief grenzen/edge, verbindt het cluster met de rest van de omgeving en het internet.
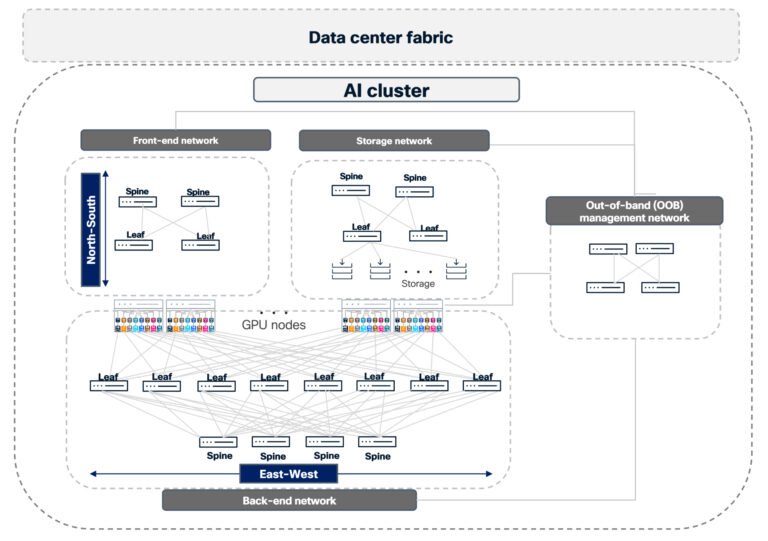
Optimale prestaties gaan niet alleen over bandbreedte, maar ook over het vermogen van de structuur om congestie, storingen en operationele complexiteit op alle niveaus te beheren naarmate de vraag naar kunstmatige intelligentie groeit.
Hoe noord-zuid-connectiviteit de efficiëntie van GPU’s beïnvloedt
Moderne kunstmatige intelligentie vertrouwt op continue en real-time interacties tussen GPU-clusters en de externe wereld. Bijvoorbeeld:
- Real-time gegevens ophalen van externe API’s of bedrijfsbronnen en partnersystemen
- Snel uploaden van trainingssets en model checkpoints vanuit high-performance opslagstructuren
- Uitvoeren van dynamische contextuele zoekopdrachten van vector databases en zoekindexen voor RAG- en agent-based workflows
- Het leveren van hoge QPS inferenties voor gebruikersgerichte applicaties en interne services
Deze modellen genereren:
- Onverwachte en onvoorspelbare belastingen: Batch/distributie-inferentiewerkzaamheden kunnen plotseling aanzienlijke bandbreedte verbruiken, uplink en kernverbindingen belasten.
- Beperkte budgetten voor latentie en jitter: Zelfs congestie of kortdurende microbursts kunnen head-of-line blokkades veroorzaken en de GPU-pipelines vertragen.
- Risico op statische hotspots: Traditionele statische hashing met Equal-Cost Multi-Pathing (ECMP) kan niet omgaan met veranderende linkgebruik, wat leidt tot verstopte paden en onderbenutte capaciteit elders.
Om de GPU’s volledig te benutten, moet het noord-zuid-netwerk gevoelig zijn voor congestie, veerkrachtig en gemakkelijk op grote schaal te beheren zijn.
Vereenvoudiging van de AI-infrastructuur met geconvergeerde front-end en storage netwerken
Vele toonaangevende AI-implementaties convergeren front-end en storage verkeer op een unified high-performance Ethernet-structuur, los van het oost-west verkeer verwerkt door GPU’s. Deze architecturale benadering wordt gedreven door zowel prestatie-eisen als operationele efficiëntie, waardoor klanten optiek en bekabeling kunnen hergebruiken en tegelijkertijd kunnen profiteren van bestaande investeringen in Clos-fabric, wat aanzienlijk kosten en complexiteit van bekabeling vermindert.
Deze geconvergeerde noord-zuid structuur:
- Biedt toegang tot high-performance storage op leaf-spine architecturen met 400G/800G capaciteit
- Transporteert hostbeheer en controleverkeer van management nodes naar processing en storage nodes
- Verbindt met border leaf switches of core switches voor externe connectiviteit en tenant in/out

De Cisco N9000 switches met Cisco NX-OS zijn speciaal ontworpen voor deze geïntegreerde structuren, waarbij zowel de schaalbaarheid als throughput vereist zijn in moderne front-end en storage AI-netwerken. Door zwaar en voorspelbaar storage verkeer te combineren met lichtere en latency-gevoelige front-end applicatiestromen, kunt u de efficiëntie van uw fabric maximaliseren wanneer deze correct is ontworpen.
Optimalisatie van AI-verkeer met Cisco Silicon One en Cisco NX-OS
Het managen van noord-zuid AI-verkeer betekent niet alleen het samenbrengen van inference, storage en training workloads op één netwerk, maar ook het aanpakken van uitdagingen met betrekking tot het convergeren van storage netwerken verbonden met verschillende endpoints. Dit omvat het optimaliseren van elk type verkeer om latentie te minimaliseren en prestatiedalingen tijdens congestie te voorkomen.
In moderne AI-infrastructuren vereisen verschillende workloads verschillende behandelingen:
- Inference verkeer vereist lage en voorspelbare latentie.
- Training verkeer vereist maximale throughput.
- Storage verkeer kan verschillende patronen hebben tussen high-performance storage, standard storage en shared storage.
Terwijl de back-end structuur voornamelijk RDMA (Remote Direct Memory Access) verkeer beheert zonder verlies, vervoert de geconvergeerde front-end en storage structuur een mix van verkeerstypen. Zonder Quality of Service (QoS) en effectieve load balancing mechanismen, kunnen plotselinge data management of user bursts leiden tot packet loss, wat rampzalig is voor strikte ROCEv2 vereisten zonder dataverlies. Daarom werken Cisco Silicon One en Cisco NX-OS samen, met dynamische load balancing (DLB) die zowel op flowlet- als pakketniveau werkt, allemaal georkestreerd via geavanceerde beleidscontrole.
Onze aanpak maakt gebruik van Cisco Silicon One application-specific integrated circuits (ASICs) in combinatie met Cisco NX-OS intelligence om real-time, op beleid gebaseerd en verkeersgevoelig load balancing te leveren dat zich aanpast. Dit omvat:
- Pakketgebaseerd DLB: Wanneer endpoints (zoals SuperNICs) out-of-order delivery kunnen verwerken, verdeelt de pakketmodus individuele pakketten over alle beschikbare links in een ECMP DLB groep. Dit maximaliseert het gebruik van links en verlicht direct congestie hotspots, essentieel voor hectische AI workloads.
- Flowlet-gebaseerde DLB: Voor verkeer dat in volgorde moet worden afgeleverd, verdeelt flowlet-gebaseerde DLB het verkeer bij burst natuurlijke grenzen. Door gebruik te maken van realtime congestie- en vertraging parameters gemeten door Cisco Silicon One, routeert het systeem elk burst slim naar de minst gebruikte ECMP pad, waardoor de stroomintegriteit behouden blijft en netwerkbronnen geoptimaliseerd worden.
- Policy-gebaseerde preferentiële behandeling: QoS criteria overschrijven het standaardgedrag met overeenkomstcriteria zoals DSCP (Differentiated Services Code Point) tags of Access Control Lists (ACL’s). Dit maakt selectieve packet load balancing mogelijk voor specifieke hoog-prioritaire of congestie-gevoelige stromen, waardoor elk type verkeer optimaal wordt behandeld.
- Cointegratie met traditionele ECMP: DLB verkeer maakt gebruik van dynamische en telemetrie-gebaseerde selectie terwijl niet-DLB stromen nog steeds traditionele ECMP gebruiken. Dit maakt incrementele adoptie en gerichte optimalisatie mogelijk zonder een hoge upgrade van de gehele infrastructuur te vereisen.
Deze gemengde aanpak is bijzonder nuttig voor noord-zuidstromen zoals storage, checkpoints en database toegang, waar congestiebewustzijn en zelfs gebruik direct vertaalbaar zijn naar een betere GPU-efficiëntie.
Schaalbaarheid van AI-activiteiten met behulp van Cisco Nexus One met Nexus Dashboard
Cisco Nexus One is een geïntegreerde oplossing die netwerkintelligentie biedt van silicium tot software, operationeel gemaakt via on-premise Cisco Nexus Dashboard en cloud-beheerde Cisco Hyperfabric. Het levert de nodige intelligentie om betrouwbare en toekomstbestendige stoffen op grote schaal te beheren met gegarandeerde prestaties.
Naarmate AI-clusters en netwerkstructuren groeien, wordt operationele eenvoud essentieel. Met Cisco Nexus Dashboard krijg je een geünificeerd operationeel niveau voor provisioning, monitoring en probleemoplossing naadloos in de hele multi-fabric omgeving.
In een AI-datacenter maakt dit een geünificeerde ervaring, vereenvoudigde automatisering en AI-werklastobservatie mogelijk. Door Cisco Nexus Dashboard te gebruiken, kunnen operators configuraties en beleidsregels beheren voor AI-clusters en andere stoffen vanuit één controlepunt, waardoor de implementatiekosten en wijzigingsbeheer aanzienlijk worden verminderd.

Nexus Dashboard vereenvoudigt automatisering door modellen en beleidsworkflows op basis van beleid te bieden om de beste praktijken van Explicit Congestion Notification (ECN), Priority Flow Control (PFC) en load balancing configuraties tussen verschillende stoffen te implementeren, waardoor aanzienlijk minder handmatige inspanningen nodig zijn.

Met behulp van Cisco Nexus Dashboard krijg je end-to-end zichtbaarheid op AI-workloads in de hele stack, waardoor real-time monitoring van netwerken, NIC’s, GPU’s en gedistribueerde verwerkingsknooppunten mogelijk is.
Paul Arends
“Ik ben Paul Arends, afgestudeerd in Bedrijfskunde aan de Universidad Complutense en met een master in Personeelsmanagement en Organisatieontwikkeling aan ESIC. Ik ben geïnteresseerd in netwerken en social media en richt mijn professionele ontwikkeling op talentmanagement en organisatieverandering.”
 Paul Arends
Paul Arends- Cisco
- mei 7, 2026
- 3 views
Partner van Cisco Network Apps Marketplace bij Cisco Live 2026
Cisco Live US 2026 staat voor de deur en het evenement van dit jaar belooft groter en beter te worden dan ooit. We stellen een indrukwekkende line-up samen van 24…

- Paul Arends
- Cisco
- mei 7, 2026
- 2 views
Het ontwikkelen van de klinische datastructuur voor agenten
Onlangs had ik het voorrecht om een indrukwekkend panel voor Cisco CX te modereren: “Scaling AI in Healthcare: From Experimentation to Production.” Nu we ons op het kruispunt bevinden van…




